
오늘도 어김없이 개발자가 되기 위한 고단한 여정을 보내고 있던 와타시.. 그러던 와중 네이버 쇼핑과 네이버의 검색 결과 제공 방식이 좀 다르다는 것을 알게 된다.
백문불여일견 바로 확인부터 해보도록 하자.
🟩네이버 검색결과
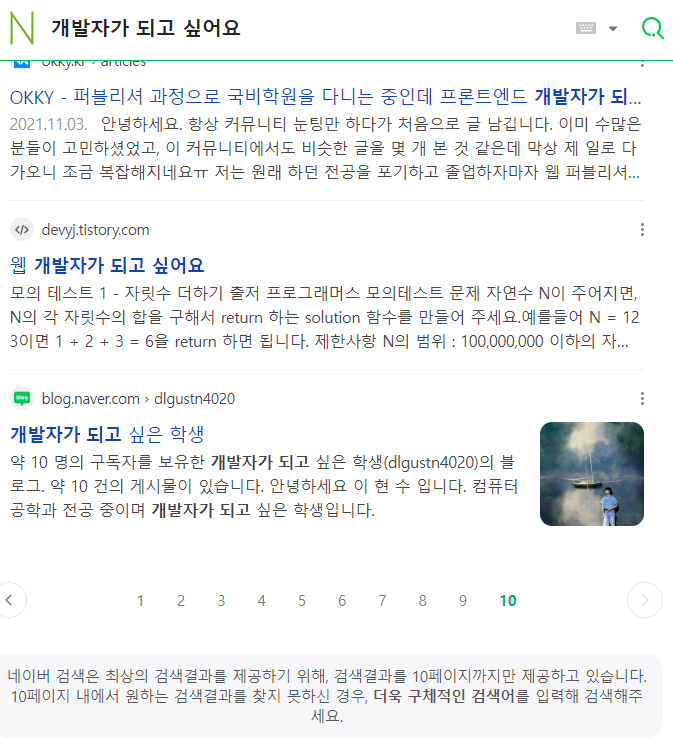
우선 네이버에서 검색어를 입력했을 경우이다. 검색 결과 최하단에 다음과 같은 문구가 적혀있다.
네이버 검색은 최상의 검색결과를 제공하기 위해, 검색결과를 10페이지까지만 제공하고 있습니다.
위 문구를 보고 단순하게 "아~ 네이버는 10페이지만 제공하는구나 ㅎㅎ" 하고 넘어갈 수 있겠지만, 우리는 개발자를 꿈꾸기에 이러한 정책에 대해서도 분석해볼 필요가 있다.
🟦왜 10 페이지만 제공을 할까?
1. 선별하기 위해
안내 문구에서 가장 중요한 키워드라고 생각되는 최상의 검색결과에 대해서 생각해보자. 나는 여기서 말하는 최상의 검색결과는 키워드와 가장 관련도가 높은 대상들을 의미한다고 생각한다. 왜냐하면 다른 검색 기능들과는 달리 검색에 조건을 추가할 수 없기 때문이다 (최신순, 추천순, 댓글순 등)
따라서 관련도가 높은 대상들을 선별하는 과정이 있을 것이고, 그 과정을 통해 데이터를 선별하다보면 10페이지 이상의 결과를 반환했을 때 적합하지 않은 결과물들이 포함되어 최상의 검색결과를 제공할 수 없게 되기 때문이지 않을까? + ( 스팸, 광고성 게시물들도 처리해야 할텐데 정말 까다롭다... )
2. 성능을 위해
네이버는 키워드의 대상이 되는 데이터가 무수히 많다. 블로그, 카페, 지식IN, 쇼핑, 뉴스 등 여러 도메인이 존재하고 도메인 하나하나가 가지고 있는 데이터의 수 또한 무수히 많을 것이다. 즉, 수 많은 데이터를 대상을 조회하여 키워드에 일치하는 데이터들을 반환해야 한다.
각각의 테이블에 따로 쿼리를 날리는 것인지 다중 JOIN을 사용하는 것인지까지는 파악할 수 없지만, 어느쪽이든 대상이 많아질수록 성능에 이슈가 생기기 마련이다. 따라서, 최상의 검색결과를 제공하면서도 빠른 시간 내에 응답하기 위해서 10페이지로 제한을 두는 정책을 세웠을 것이라고 추측해볼 수 있다.
그렇다면 네이버 쇼핑의 경우는 어떨까?
🟩네이버 쇼핑 검색결과
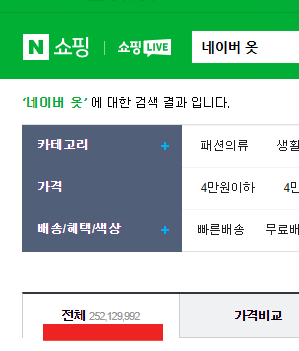
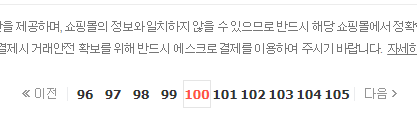
가장 먼저 눈에 보였던 것은 검색결과 데이터의 수를 보여준다는 것이다. 놀라운 점은 2억개가 넘는 데이터를 조회하는데도 응답을 받기까지 그리 오래걸리지 않는다. 그냥 평소와 똑같은 것 같다. 게다가 페이지도 10페이지 이상 제공한다. 수작업으로 100페이지까지 이동해보았는데 정상적으로 동작한다.
URL을 살펴보면 https://search.shopping.naver.com/search/all?adQuery=키워드&origQuery=키워드&pagingIndex=3&pagingSize=40&productSet=total&query=키워드sort=rel×tamp=&viewType=list 로 구성되어 있어서 마찬가지로 pagingIndex 값을 조작하여여 페이지 이동이 가능했다.
다만 네이버와는 달리 네이버 쇼핑에서의 페이지 조작에는 특이한 점이 존재했는데, 검색 키워드에 따라 페이지 한계값이 다르다는 것이다. 예를들어 겨울옷 검색 키워드를 높은 가격순으로 pagingIndex=201, pageSize=40 으로 조회했을 때는 다음과 같은 결과가 나온다.
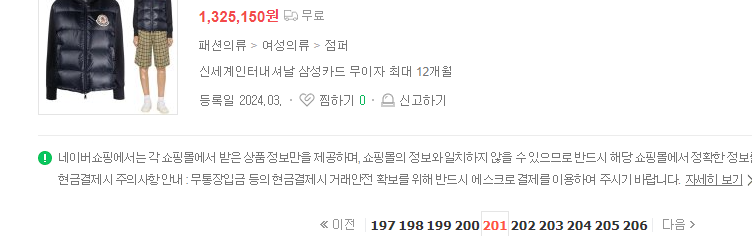
여기서 201페이지보다 큰 곳으로 이동하더라도 201페이지의 결과와 동일한 결과를 반환할 뿐 변경되는 점은 없다.
그런데 옷 검색 키워드를 높은 가격순으로 pagingIndex=201, pageSize=40 을 조회하면 검색 결과가 없다고 나온다.

다시 페이지를 pagingIndex를 198로 낮추면 잘 조회되는 것으로 보아 키워드 대상에 따라 최대로 보여줄 페이지의 개수가 다르다는 것을 알 수 있다. 다만, 위와 같이 검색 결과가 없다는 페이지를 보여주는 경우와 그렇지 않은 경우 그리고 이를 결정하는 조건에 대해서는 파악하기 어려울 것 같다.

여기서 "조회되는 데이터는 2억개가 넘는데 200페이지 이상 갈 수 없다면 나머지는 어떻게 확인할 수 있는 거지?"라는 생각이 들 수도 있는데, 네이버 쇼핑은 위와 같이 다양한 검색 조건을 추가하여 대상을 특정할 수 있다. 따라서 원하는 데이터가 나오도록 검색어를 튜닝하면 애초에 200페이지까지 갈 일이 없다는 것!
🟦 두 도메인은 왜 다를까?
두 도메인에서 페이지 상한선을 다르게 책정한 이유는 무엇일까? 나는 각 도메인이 다루는 데이터의 성질이 다르기 때문이라고 생각한다.
네이버 쇼핑의 경우 상품에 대한 정보만 반환하면 된다. 조회 대상이 한정적이라는 것인데, '장난감'을 검색하면 장난감을 가져오면 된다. 또한, 거의 모든 상품이 카테고리로 분류가 가능하기 때문에 관련도가 높은 데이터를 특정하여 가져오는 것이 어렵지 않아 많은 데이터를 제공하더라도 검색의 질이 크게 떨어지지 않을 것 이다.
반면에 네이버의 경우 검색 키워드가 상품에 국한되지 않아 대상의 범위도 넓고, 키워드의 형태도 더 자유롭다. 즉, 카테고리화 되어있지 않아 대상을 특정하기 어렵다. 대상 특정이 어렵기 때문에 단순히 키워드가 포함된 결과를 마구잡이로 반환하게 된다면 검색 결과의 질이 떨어지게 되고, 이는 검색 포털로서의 장점을 잃게 되는 길이라고 생각한다. 따라서 검색결과를 선별해서 제공하기 위해 이러한 정책이 필요하지 않았을까?
🟦통계를 이용하는 건가?
위에서 검색결과 데이터의 수를 보여주는 부분이 신기하다고 했는데, 이것저것 실험하다보니 더 신기한 것을 발견했다.

위 이미지는 네이버 랭킹순 -> 낮은 가격순 -> 네이버 랭킹순으로 정렬 조건만 바꾸어 순차적으로 요청을 보냈을 때의 결과이다. 어떤 정렬조건을 사용하냐에 따라 전체 데이터의 수가 변하는 것을 볼 수 있었다. 뿐만 아니라 같은 네이버 랭킹순임에도 요청마다 전체 데이터의 개수에서 꽤나 큰 차이를 보인다. 단순히 조건을 바꾸는 그 짧은 시간 동안 저렇게나 많은 데이터가 삽입, 삭제되지는 않았을 것이다.
따라서 나는 네이버 쇼핑이 실제로 DB에서 데이터의 개수를 매번 COUNT 하여 반환하는 것이 아니며 통계를 활용하고 있는 것이지 않을까라는 추측을 하게 되었다.
또 다른 추측의 근거로 전체 데이터 수를 제공하는 목적에 대해서도 생각해보았다.
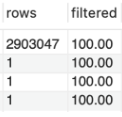
MySQL의 EXPLAIN을 통해 쿼리 실행 계획을 보면 행을 찾기 위해 접근한 데이터의 모든 행(rows)를 확인할 수 있는데, 이 값은 실제로 접근한 모든 행을 나타내는 것이 아니라 MySQL이 테이블 정보를 분석하여 예측한 값을 나타낸다. 우리는 이 실행 계획을 통해 반한된 rows가 실제 조회되는 데이터 건수와 완벽히 일치하기까지는 바라지 않는다. 왜냐하면 예측한 값만으로도 튜닝 대상을 파악하는 데에는 큰 어려움이 없기 때문이다.
네이버 쇼핑의 결과도 마찬가지일 것이다. 사용자는 검색어를 튜닝하기 위해 전체 결과의 수를 완벽하게 알 필요가 없다. 옷이라는 검색을 통해 2억개의 결과를 얻었다면, 사용자는 원하는 옷을 사기 위해 검색어를 좀 더 튜닝하여 검색 대상을 축소하려 할 것이다. 다음과 같이 겨울 옷 ( 1,500 만개 ) -> 남자 패딩( 500 만개 ) 의 흐름으로 대상을 축소하는 과정에는 전체 결과의 근삿값만 있더라도 충분히 활용이 가능하기 때문에 통계를 사용하더라도 충분할 것이다.
추측만 하면 아쉬우니 이 추측을 바탕으로 나라면 어떻게 네이버 쇼핑과 같이 구현할 것인지 생각해보자.
🟦What if
(미흡한 지식으로 상상 구현하는 과정이기 때문에 잘못된 정보가 있을 수 있습니다!)
통계 데이터를 생성하고 관리하기 위해서는 Spring Batch를 이용해 볼 수 있을 것 같다. Spring Batch를 사용해본 적은 없지만, Spring Framework 라는 점에서 Spring의 장점인 DI, AOP 등을 활용할 수 있고 Chunk 단위로 데이터를 일괄적으로 처리할 수 있고 스케줄링을 통해 자동화가 가능하다는 점이 통계 데이터를 다루는 데에 적합하다고 생각하기 때문이다.
id | keyword | result
1 | 옷 | 250,000,000
2 | 구두 | 300,000
3 | 코트 | 4,500,000Batch를 이용해 키워드별 상품 조회 결과에 대한 통계 테이블을 생성하는데 대략 위와 같은 형태가 될 것 같다. (수치는 대략적으로 정함) 이렇게 Batch를 이용하여 통계 데이터를 만들어둔다면 매번 COUNT 쿼리를 날리지 않아도 전체 데이터의 수를 가져와 사용할 수 있게 된다.
이제 조회 요청이 들어왔을 때 들어온 키워드에 해당하는 result가 일정 크기를 넘어간다면 상품 테이블에서 정책으로 설정한 페이지에 해당하는 데이터까지만 조회하도록 한다. (result가 1억을 넘어가면 200페이지까지만 조회한다는 정책을 세웠다고 가정)
이제 통계 데이터를 활용하여 '옷'이라는 키워드가 들어오면 result가 1억을 넘어가기 때문에 200페이지까지만 결과를 반환하도록 한다. 전체 결과는 통계 테이블을 통해 반환한다. DB는 검색어 기반으로 조회 성능이 뛰어나다는 Elsatic Search를 사용하면 좋을 것 같은데, 이 역시 아직은 사용 경험이 없어서 좀 더 공부를 해봐야 할 것 같다.
마무리..
이번 분석 과정을 통해 개발을 하는 데에 있어서 도메인 이해도가 얼마나 중요한지 느낄 수 있는 시간이었던 것 같다. 이전 포스팅에서 COUNT 쿼리 한계에 대한 내용을 다뤘었는데, 사실 아직 포스팅을 하지 않았지만 결국 마땅한 해결법을 찾지 못하여 Cursor 방식을 통해 한 번 더 최적화를 진행한 상태이다. 그런데 이번 네이버 쇼핑 분석 과정을 진행하면서 꼭 데이터 전체를 조회할 수 있게 해야 하는 건가? 라는 물음을 던질 수 있게 되었다.
네이버 쇼핑의 조회 과정처럼 일정 페이지 이상으로는 조회가 되지 않도록 정책을 세우고 검색 또는 필터링 기능을 통해 조회 사용자가 검색 대상을 추려가도록 하는 흐름을 이용하거나 COUNT 결과를 재활용하는 식으로 구현했더라면 기존의 OFFSET 방식을 유지해도 괜찮지 않았나라는 생각이 든다. 조금 늦은 감이 없진 않지만 이렇게라도 새로운 시선을 가질 수 있게 되서 다행이다.
오늘도 어김없이 개발자가 되기 위한 고단한 여정을 보내고 있던 와타시.. 그러던 와중 네이버 쇼핑과 네이버의 검색 결과 제공 방식이 좀 다르다는 것을 알게 된다.
백문불여일견 바로 확인부터 해보도록 하자.
🟩네이버 검색결과
우선 네이버에서 검색어를 입력했을 경우이다. 검색 결과 최하단에 다음과 같은 문구가 적혀있다.
네이버 검색은 최상의 검색결과를 제공하기 위해, 검색결과를 10페이지까지만 제공하고 있습니다.
위 문구를 보고 단순하게 "아~ 네이버는 10페이지만 제공하는구나 ㅎㅎ" 하고 넘어갈 수 있겠지만, 우리는 개발자를 꿈꾸기에 이러한 정책에 대해서도 분석해볼 필요가 있다.
🟦왜 10 페이지만 제공을 할까?
1. 선별하기 위해
안내 문구에서 가장 중요한 키워드라고 생각되는 최상의 검색결과에 대해서 생각해보자. 나는 여기서 말하는 최상의 검색결과는 키워드와 가장 관련도가 높은 대상들을 의미한다고 생각한다. 왜냐하면 다른 검색 기능들과는 달리 검색에 조건을 추가할 수 없기 때문이다 (최신순, 추천순, 댓글순 등)
따라서 관련도가 높은 대상들을 선별하는 과정이 있을 것이고, 그 과정을 통해 데이터를 선별하다보면 10페이지 이상의 결과를 반환했을 때 적합하지 않은 결과물들이 포함되어 최상의 검색결과를 제공할 수 없게 되기 때문이지 않을까? + ( 스팸, 광고성 게시물들도 처리해야 할텐데 정말 까다롭다... )
2. 성능을 위해
네이버는 키워드의 대상이 되는 데이터가 무수히 많다. 블로그, 카페, 지식IN, 쇼핑, 뉴스 등 여러 도메인이 존재하고 도메인 하나하나가 가지고 있는 데이터의 수 또한 무수히 많을 것이다. 즉, 수 많은 데이터를 대상을 조회하여 키워드에 일치하는 데이터들을 반환해야 한다.
각각의 테이블에 따로 쿼리를 날리는 것인지 다중 JOIN을 사용하는 것인지까지는 파악할 수 없지만, 어느쪽이든 대상이 많아질수록 성능에 이슈가 생기기 마련이다. 따라서, 최상의 검색결과를 제공하면서도 빠른 시간 내에 응답하기 위해서 10페이지로 제한을 두는 정책을 세웠을 것이라고 추측해볼 수 있다.
그렇다면 네이버 쇼핑의 경우는 어떨까?
🟩네이버 쇼핑 검색결과
가장 먼저 눈에 보였던 것은 검색결과 데이터의 수를 보여준다는 것이다. 놀라운 점은 2억개가 넘는 데이터를 조회하는데도 응답을 받기까지 그리 오래걸리지 않는다. 그냥 평소와 똑같은 것 같다. 게다가 페이지도 10페이지 이상 제공한다. 수작업으로 100페이지까지 이동해보았는데 정상적으로 동작한다.
URL을 살펴보면 https://search.shopping.naver.com/search/all?adQuery=키워드&origQuery=키워드&pagingIndex=3&pagingSize=40&productSet=total&query=키워드sort=rel×tamp=&viewType=list 로 구성되어 있어서 마찬가지로 pagingIndex 값을 조작하여여 페이지 이동이 가능했다.
다만 네이버와는 달리 네이버 쇼핑에서의 페이지 조작에는 특이한 점이 존재했는데, 검색 키워드에 따라 페이지 한계값이 다르다는 것이다. 예를들어 겨울옷 검색 키워드를 높은 가격순으로 pagingIndex=201, pageSize=40 으로 조회했을 때는 다음과 같은 결과가 나온다.
여기서 201페이지보다 큰 곳으로 이동하더라도 201페이지의 결과와 동일한 결과를 반환할 뿐 변경되는 점은 없다.
그런데 옷 검색 키워드를 높은 가격순으로 pagingIndex=201, pageSize=40 을 조회하면 검색 결과가 없다고 나온다.
다시 페이지를 pagingIndex를 198로 낮추면 잘 조회되는 것으로 보아 키워드 대상에 따라 최대로 보여줄 페이지의 개수가 다르다는 것을 알 수 있다. 다만, 위와 같이 검색 결과가 없다는 페이지를 보여주는 경우와 그렇지 않은 경우 그리고 이를 결정하는 조건에 대해서는 파악하기 어려울 것 같다.
여기서 "조회되는 데이터는 2억개가 넘는데 200페이지 이상 갈 수 없다면 나머지는 어떻게 확인할 수 있는 거지?"라는 생각이 들 수도 있는데, 네이버 쇼핑은 위와 같이 다양한 검색 조건을 추가하여 대상을 특정할 수 있다. 따라서 원하는 데이터가 나오도록 검색어를 튜닝하면 애초에 200페이지까지 갈 일이 없다는 것!
🟦 두 도메인은 왜 다를까?
두 도메인에서 페이지 상한선을 다르게 책정한 이유는 무엇일까? 나는 각 도메인이 다루는 데이터의 성질이 다르기 때문이라고 생각한다.
네이버 쇼핑의 경우 상품에 대한 정보만 반환하면 된다. 조회 대상이 한정적이라는 것인데, '장난감'을 검색하면 장난감을 가져오면 된다. 또한, 거의 모든 상품이 카테고리로 분류가 가능하기 때문에 관련도가 높은 데이터를 특정하여 가져오는 것이 어렵지 않아 많은 데이터를 제공하더라도 검색의 질이 크게 떨어지지 않을 것 이다.
반면에 네이버의 경우 검색 키워드가 상품에 국한되지 않아 대상의 범위도 넓고, 키워드의 형태도 더 자유롭다. 즉, 카테고리화 되어있지 않아 대상을 특정하기 어렵다. 대상 특정이 어렵기 때문에 단순히 키워드가 포함된 결과를 마구잡이로 반환하게 된다면 검색 결과의 질이 떨어지게 되고, 이는 검색 포털로서의 장점을 잃게 되는 길이라고 생각한다. 따라서 검색결과를 선별해서 제공하기 위해 이러한 정책이 필요하지 않았을까?
🟦통계를 이용하는 건가?
위에서 검색결과 데이터의 수를 보여주는 부분이 신기하다고 했는데, 이것저것 실험하다보니 더 신기한 것을 발견했다.
위 이미지는 네이버 랭킹순 -> 낮은 가격순 -> 네이버 랭킹순으로 정렬 조건만 바꾸어 순차적으로 요청을 보냈을 때의 결과이다. 어떤 정렬조건을 사용하냐에 따라 전체 데이터의 수가 변하는 것을 볼 수 있었다. 뿐만 아니라 같은 네이버 랭킹순임에도 요청마다 전체 데이터의 개수에서 꽤나 큰 차이를 보인다. 단순히 조건을 바꾸는 그 짧은 시간 동안 저렇게나 많은 데이터가 삽입, 삭제되지는 않았을 것이다.
따라서 나는 네이버 쇼핑이 실제로 DB에서 데이터의 개수를 매번 COUNT 하여 반환하는 것이 아니며 통계를 활용하고 있는 것이지 않을까라는 추측을 하게 되었다.
또 다른 추측의 근거로 전체 데이터 수를 제공하는 목적에 대해서도 생각해보았다.
MySQL의 EXPLAIN을 통해 쿼리 실행 계획을 보면 행을 찾기 위해 접근한 데이터의 모든 행(rows)를 확인할 수 있는데, 이 값은 실제로 접근한 모든 행을 나타내는 것이 아니라 MySQL이 테이블 정보를 분석하여 예측한 값을 나타낸다. 우리는 이 실행 계획을 통해 반한된 rows가 실제 조회되는 데이터 건수와 완벽히 일치하기까지는 바라지 않는다. 왜냐하면 예측한 값만으로도 튜닝 대상을 파악하는 데에는 큰 어려움이 없기 때문이다.
네이버 쇼핑의 결과도 마찬가지일 것이다. 사용자는 검색어를 튜닝하기 위해 전체 결과의 수를 완벽하게 알 필요가 없다. 옷이라는 검색을 통해 2억개의 결과를 얻었다면, 사용자는 원하는 옷을 사기 위해 검색어를 좀 더 튜닝하여 검색 대상을 축소하려 할 것이다. 다음과 같이 겨울 옷 ( 1,500 만개 ) -> 남자 패딩( 500 만개 ) 의 흐름으로 대상을 축소하는 과정에는 전체 결과의 근삿값만 있더라도 충분히 활용이 가능하기 때문에 통계를 사용하더라도 충분할 것이다.
추측만 하면 아쉬우니 이 추측을 바탕으로 나라면 어떻게 네이버 쇼핑과 같이 구현할 것인지 생각해보자.
🟦What if
(미흡한 지식으로 상상 구현하는 과정이기 때문에 잘못된 정보가 있을 수 있습니다!)
통계 데이터를 생성하고 관리하기 위해서는 Spring Batch를 이용해 볼 수 있을 것 같다. Spring Batch를 사용해본 적은 없지만, Spring Framework 라는 점에서 Spring의 장점인 DI, AOP 등을 활용할 수 있고 Chunk 단위로 데이터를 일괄적으로 처리할 수 있고 스케줄링을 통해 자동화가 가능하다는 점이 통계 데이터를 다루는 데에 적합하다고 생각하기 때문이다.
id | keyword | result
1 | 옷 | 250,000,000
2 | 구두 | 300,000
3 | 코트 | 4,500,000Batch를 이용해 키워드별 상품 조회 결과에 대한 통계 테이블을 생성하는데 대략 위와 같은 형태가 될 것 같다. (수치는 대략적으로 정함) 이렇게 Batch를 이용하여 통계 데이터를 만들어둔다면 매번 COUNT 쿼리를 날리지 않아도 전체 데이터의 수를 가져와 사용할 수 있게 된다.
이제 조회 요청이 들어왔을 때 들어온 키워드에 해당하는 result가 일정 크기를 넘어간다면 상품 테이블에서 정책으로 설정한 페이지에 해당하는 데이터까지만 조회하도록 한다. (result가 1억을 넘어가면 200페이지까지만 조회한다는 정책을 세웠다고 가정)
이제 통계 데이터를 활용하여 '옷'이라는 키워드가 들어오면 result가 1억을 넘어가기 때문에 200페이지까지만 결과를 반환하도록 한다. 전체 결과는 통계 테이블을 통해 반환한다. DB는 검색어 기반으로 조회 성능이 뛰어나다는 Elsatic Search를 사용하면 좋을 것 같은데, 이 역시 아직은 사용 경험이 없어서 좀 더 공부를 해봐야 할 것 같다.
마무리..
이번 분석 과정을 통해 개발을 하는 데에 있어서 도메인 이해도가 얼마나 중요한지 느낄 수 있는 시간이었던 것 같다. 이전 포스팅에서 COUNT 쿼리 한계에 대한 내용을 다뤘었는데, 사실 아직 포스팅을 하지 않았지만 결국 마땅한 해결법을 찾지 못하여 Cursor 방식을 통해 한 번 더 최적화를 진행한 상태이다. 그런데 이번 네이버 쇼핑 분석 과정을 진행하면서 꼭 데이터 전체를 조회할 수 있게 해야 하는 건가? 라는 물음을 던질 수 있게 되었다.
네이버 쇼핑의 조회 과정처럼 일정 페이지 이상으로는 조회가 되지 않도록 정책을 세우고 검색 또는 필터링 기능을 통해 조회 사용자가 검색 대상을 추려가도록 하는 흐름을 이용하거나 COUNT 결과를 재활용하는 식으로 구현했더라면 기존의 OFFSET 방식을 유지해도 괜찮지 않았나라는 생각이 든다. 조금 늦은 감이 없진 않지만 이렇게라도 새로운 시선을 가질 수 있게 되서 다행이다.