
이번 포스팅에서는 데브코스 팀 프로젝트 진행 중에 경험했던 페이징 쿼리 최적화 과정에 대해서 소개하려고 합니다.
Steady - 배포주소, 백엔드 깃허브
개발자들을 대상으로 스터디 또는 프로젝트 인원을 모집할 때 구글 폼과 같은 외부 서비스에 의존하지 않고도 검증된 인원을 모집할 수 있도록 서비스 내에서 자체적으로 폼을 제공하고, 유저 평가 시스템을 통해 인원으 모집할 수 있는 서비스입니다.
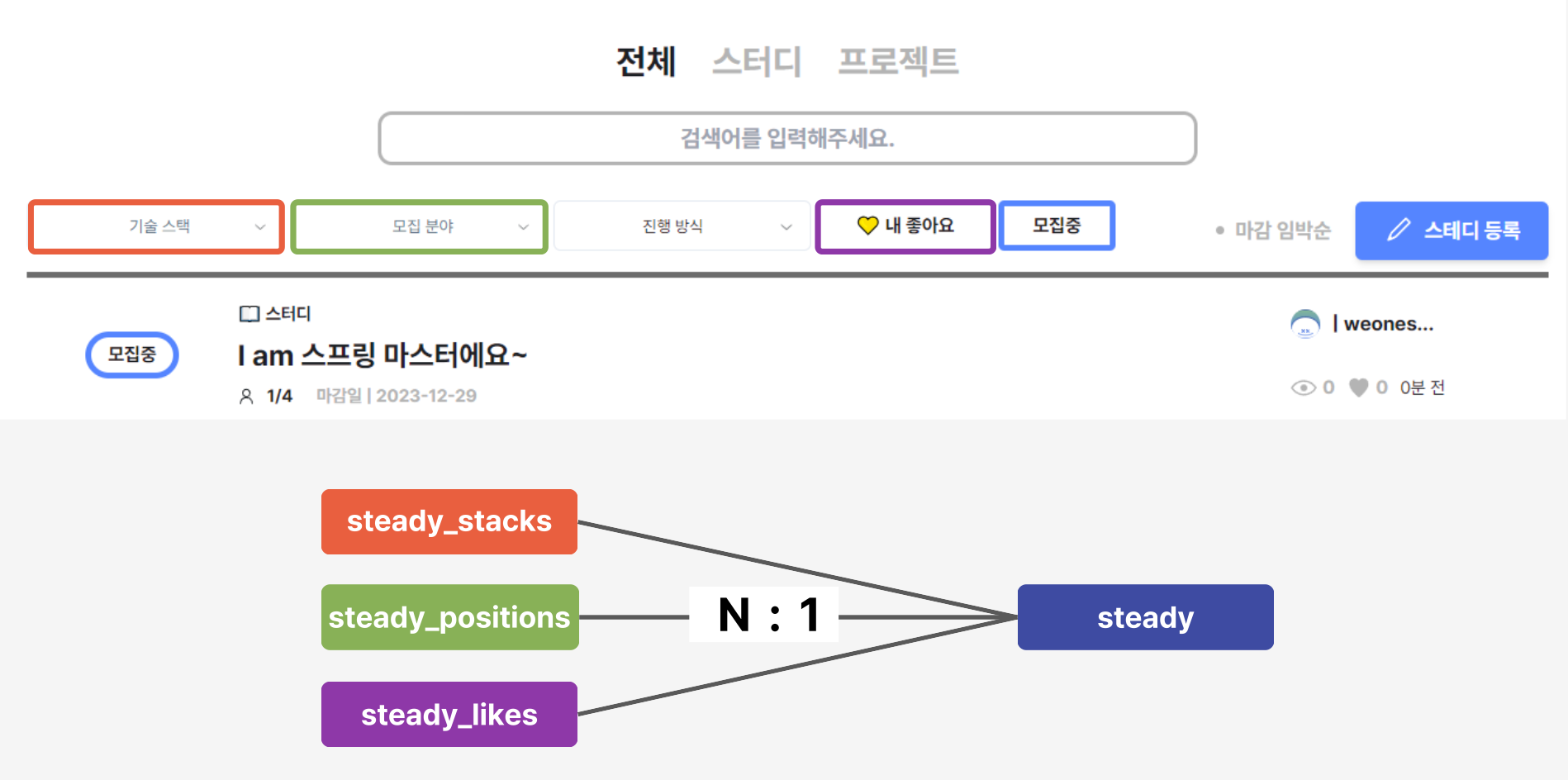
위 이미지를 통해 알 수 있듯이 steady는 기술 스택, 모집 분야, 좋아요와 일대다 관계를 맺고 있습니다. 이러한 관계를 맺고 있는 데이터들이 존재할 때 동적으로 필터링 또는 검색 조건을 통해 조회하기 위해서 QueryDsl을 사용하였습니다.
QueryDsl을 통해 작성한 메서드와 당시 DB 상황은 다음과 같습니다.
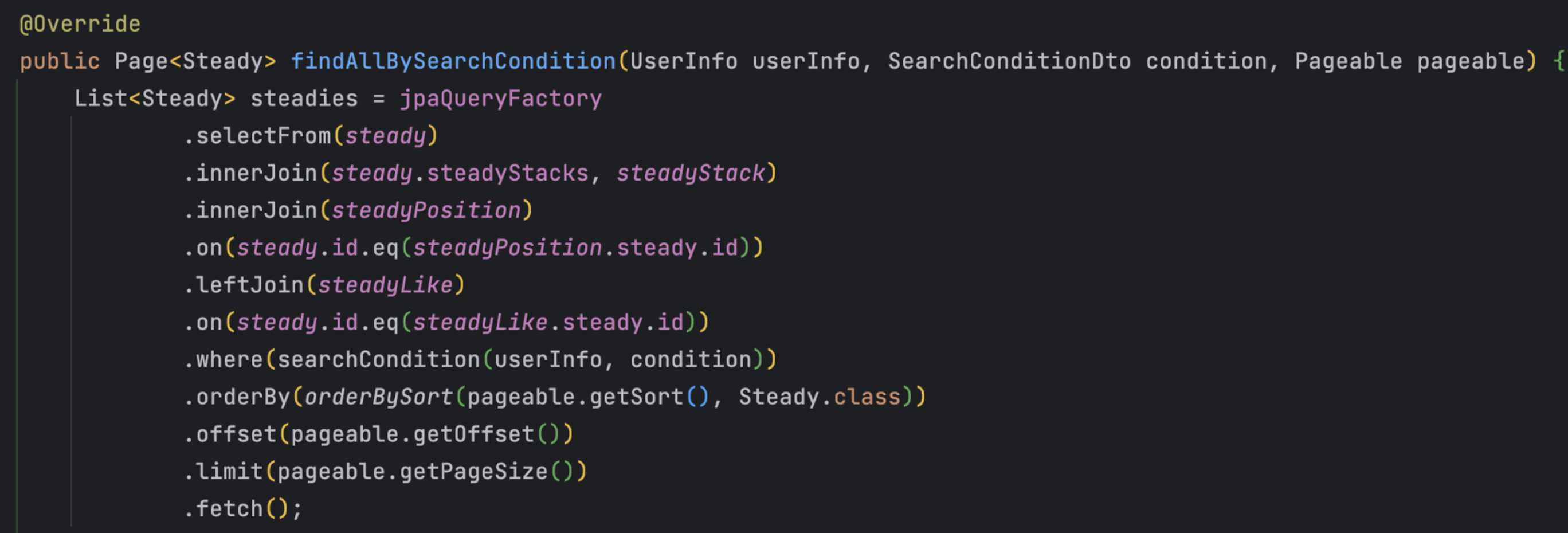
메서드에 대해서 간단히 설명하자면 steady_stack과 steady_position의 경우 항상 존재하기 때문에 Inner Join 해주었으며, steady_like의 경우 좋아요를 누르지 않았다면 존재하지 않는 경우도 있기 때문에 Left Join 을 사용하였습니다.
필터링 & 검색 조건을 처리하는 부분은 wherer 절의 searchCondition() 메서드이며, 페이징 조건은 offset = 0, limit = 10 입니다.
| 테이블 | 데이터 수 |
| steady | 125 |
| steady_stacks | 208 |
| steady_position | 182 |
| steady_likes | 20 |
위 메서드를 실행 시킨 결과는 다음과 같습니다.

페이징 조건에 따라 10개의 각기 다른 데이터가 조회되길 기대했는데 결과는 그렇지 못한 것을 확인할 수 있었습니다. DB 상에서 일대다 관계를 Join 하여 조회하면 카테시안 곱이 발생하여 중복된 데이터가 발생하기 때문이었습니다.
다행히도 해당 문제는 조회 메서드에 distinct를 추가하여 중복된 값을 제거하고 조회할 수 있도록 하면 쉽게 해결할 수 있는 문제였습니다. 그런데, 또 다른 문제점을 발견하게 됩니다.
N + 1 (feat. Fetch Join과 Paging)

메서드 실행 결과에 대한 로그 정보입니다. 요청 총 소요 시간이 553ms 로 프로젝트 환경마다 요총 소요 시간의 최적값이 상이하겠지만, 일반적으로는 300ms 이하로 나오는 것이 좋다고 알고 있습니다. 따라서 요청을 처리하는 데에 꽤나 많은 시간이 걸리고 있다는 것을 확인할 수 있었으며, 총 쿼리 카운트가 56개로 너무 많은 쿼리를 발생시키고 있는 것을 확인할 수 있었습니다.
이는 조회한 엔티티를 지연 초기화 하는 과정에서 N + 1 문제가 발생하고 었었기 때문이었습니다. N + 1 문제는 JPA를 사용하는 개발자들에게 친숙한 문제이기 때문에 저 역시 따로 깊은 고민을 하지 않고 Fetch Join 을 사용하여 해결하려고 하였습니다.
하지만 Fetch Join은 연관관계가 설정되지 않은 경우에는 적용되지 않는다는 문제점이 존재했습니다. 이는 Fetch Join의 동작 방식 때문인데, 엔티티를 조회할 때 프록시로 조회되어야 할 필드(fetch = FetchType.Lazy 가 적용된 필드)를 프록시가 아닌 실제 엔티티를 조회하여 넣어주는 방식으로 동작하기 때문입니다.
또한, 컬렉션에 Fetch Join을 사용하면 다음과 같은 경고문을 만나게 됩니다.

단순히 경고문만 출력되는 것이 아니라 아래와 같이 쿼리에도 변경점이 발생하게 됩니다.
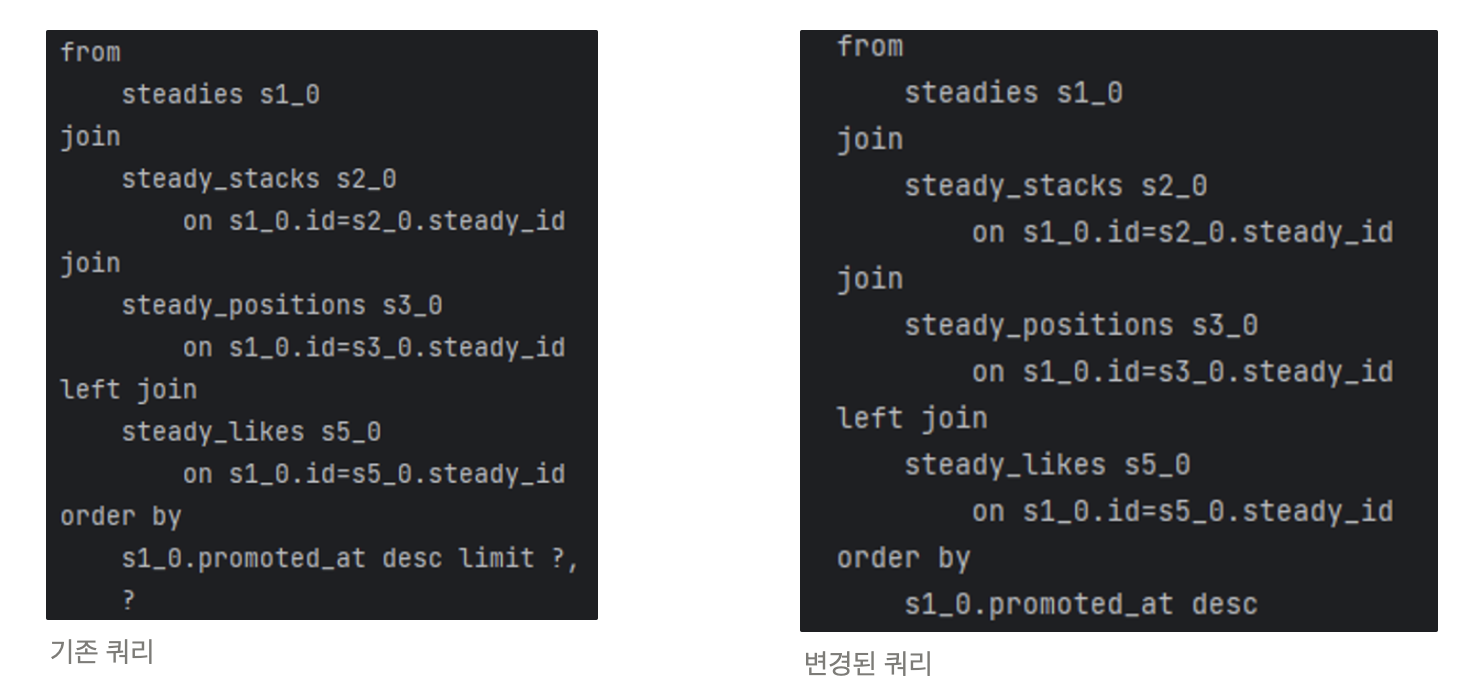
마지막 라인의 order by 절에서 offset 과 limit 에 대한 값이 사라진 것을 확인할 수 있습니다. 왜 이런 변경점이 발생하는 것일까요?
이는 일대다 관계와 같은 컬렉션 관계를 Fetch Join 하게 되면 데이터의 수가 변하기 때문에 (위의 카테시안 곱 상황) 몇 개의 row를 가져와 페이징 처리를 해야하는지 애플리케이션에서는 예측할 수 없기 때문입니다. 예측이 불가능하기 때문에 페이징 처리를 하기 위해서 Pageable 조건인 offset 과 limit을 무시하고 모든 결과를 가져와 메모리에 올린 후 페이징 처리를 진행하기 때문에 위와 같은 경고문의 출력과 쿼리의 변경이 발생하는 것이었습니다.
추가적으로 데이터의 수를 예측할 수 없기 때문에 하나의 컬렉션에 대해서만 적용이 가능합니다.
default_batch_fetch_size
Fetch Join 을 사용하여 해결하는 것에 실패하였기 때문에 또 다른 해결 방법인 default_batch_fetch_size 설정을 이용하여 해결을 시도하였습니다. 해당 설정은 지연 로딩으로 발생하는 쿼리를 지정한 크기만큼 모아두었다가 크기에 도달하면 쿼리의 in절을 통해 모아둔 쿼리를 처리하여 쿼리 발생을 최적화 해주는 기능입니다.
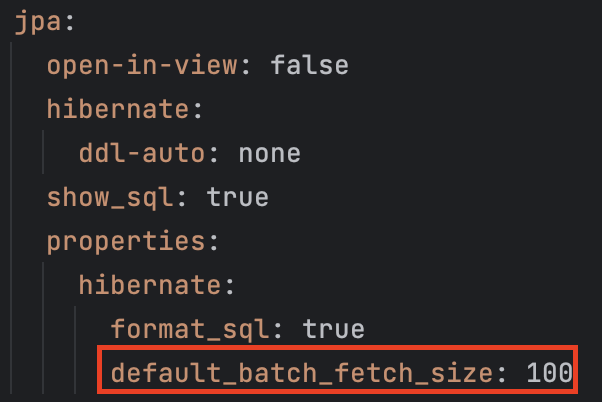

실행 결과 요청 소요 시간이 553ms -> 90ms 로 단축되었으며, 총 쿼리 카운트도 56 -> 10으로 줄어든 것을 확인할 수 있었습니다. 그런데 이 default_batch_fetch_size 의 값을 얼마로 주느냐에 따라 성능에 유의미한 차이가 있다고 하여 테스트를 해보았지만, 큰 차이를 확인할 수 없어서 해당 설정에 대해서 좀 더 조사를 해보았습니다.
우선, 데이터 베이스는 성능을 최적화하기 위해 실행한 SQL 구문과 파싱된 결과를 내부에 캐싱을 하게 됩니다. 이렇게 함으로써 같은 모양의 SQL 구문이 실행될 때 캐싱된 정보를 그대로 사용하여 효율적인 동작을 할 수 있게 되는 것입니다. Hibernate 역시 이러한 점을 인지하고 default_batch_fetch_size를 사용할 때 in 절에 들어올 수 있는 파라미터의 개수를 캐싱하여 최적화를 진행하였습니다. 이 값은 1 ~ 10, 12, 25, 50, 100 으로 총 14개의 형태를 캐싱하게 되는데, 예를 들어 값을 18로 설정하고 18개의 데이터를 조회하면 in 절에 12개의 파라미터를 받는 쿼리와 6개를 받는 쿼리로 나뉘어 조회가 일어나게 되는 것입니다.
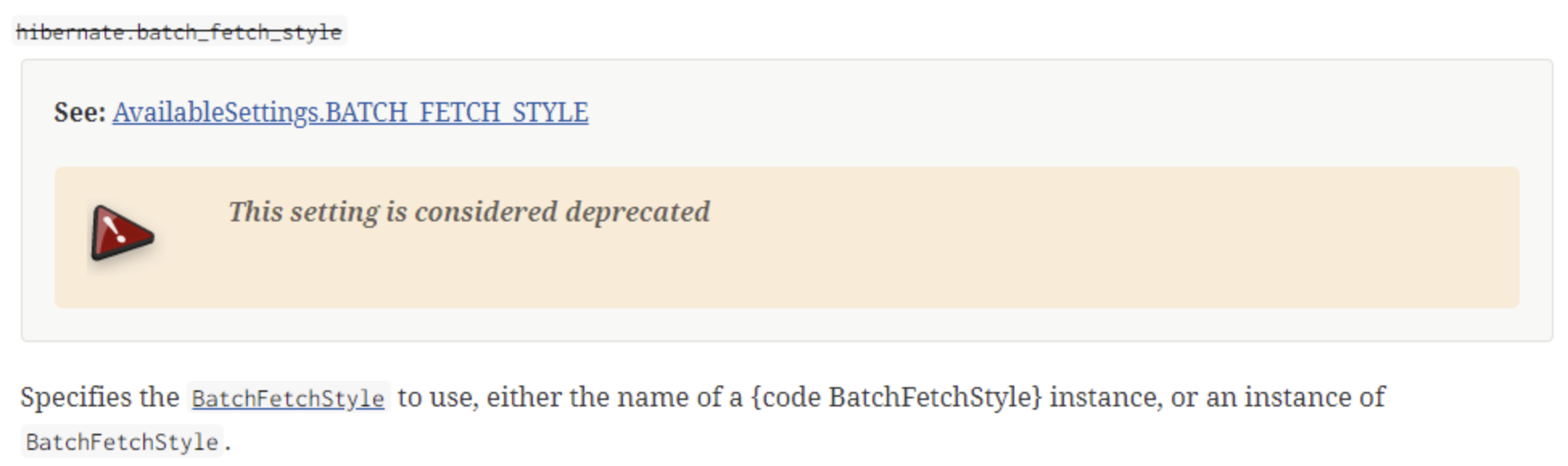
하지만 공식문서를 찾아보니 해당 옵션을 조절할 수 있는 batch_fetch_style 설정이 Hiberante 6.2 버전부터 deprecated 된 것을 확인할 수 있었습니다. 이는 default_batch_fetch_size의 동작이 변경되었기 때문인데, 기존의 where in(?) 방식으로 동작하던 것이 where array_contains(array[], ?) 방식으로 동작하게끔 변경되었다고 합니다. 이렇게 동작하면 단 2개의 파라미터만을 받아들이기 때문에 SQL 최적화에도 보다 유리하다고 합니다. (참고 : 인프런 커뮤니티)
이러한 정보를 토대로 저는 다음과 같이 정리하였습니다.
1. Hibernate 6.2 부터 default_batch_fetch_size의 동작 방식이 변경되었기 때문에 옵션 크기에 따라 SQL 최적화가 변경되진 않는다. (항상 2개의 파라미터만을 받아들이기에)
2. 크기는 몇 개의 쿼리를 모아두었다가 한 번에 쿼리를 날릴 것인가에 대한 설정이므로, DB가 부하를 견딜 수 있을만큼 지정해주면 된다. 일반적으로는 100 ~ 1000 으로 설정하길 권장한다.
3. 현재 프로젝트에서는 하나의 steady를 조회할 때 지연 초기화되는 데이터의 수가 100개를 넘어가지 않기 때문에 우선 100으로 지정한다.
아쉬운 점 (Projection, @EntityGraph)
단순히 JPA 만을 사용하는 것이 아니라 QueryDsl도 같이 사용하고 있었기 때문에 N + 1 문제가 발생하였을 때 Fetch Join만을 떠올리는 것이 아니라 Projection 을 통한 해결방법도 떠올렸으면 좋지 않았을까 하는 아쉬움을 느끼게 되었습니다. Projection을 사용하면 SELECT 절에 대상 컬럼을 포함시켜 한 번에 조회하기 때문에 N + 1 문제를 해결하기에 적합한 또 다른 선택지가 될 수 있다고 생각합니다.
@EntityGraph 를 사용한 방법 역시 N + 1 문제의 대응책으로 많이 알려진 방법인데, 이 역시 모든 결과를 조회한 후 메모리에 올려서 페이징 처리를 진행하기 때문에 해결책으로서는 적합하지 않았습니다. 또한, fetchType을 Eager로 변환하는 방식으로 동작하며 LEFT OUTER JOIN을 수행하기 때문에 데이터에 null이 존재할 수 있습니다.
'Spring' 카테고리의 다른 글
| 이벤트를 좀 더 제대로 다뤄보자 (feat. MSA & EDA) (2) | 2024.04.22 |
|---|---|
| 동시성 테스트를 통한 성능 개선하기 (2) - Spring Event (2) | 2024.04.04 |
| 조회 성능 최적화(3) - QueryDsl : SQL (0) | 2024.03.16 |
| 테스트 객체 생성 라이브러리 Instancio, Fixture Monkey (feat. Test Fixture) (0) | 2024.02.05 |
이번 포스팅에서는 데브코스 팀 프로젝트 진행 중에 경험했던 페이징 쿼리 최적화 과정에 대해서 소개하려고 합니다.
Steady - 배포주소, 백엔드 깃허브
개발자들을 대상으로 스터디 또는 프로젝트 인원을 모집할 때 구글 폼과 같은 외부 서비스에 의존하지 않고도 검증된 인원을 모집할 수 있도록 서비스 내에서 자체적으로 폼을 제공하고, 유저 평가 시스템을 통해 인원으 모집할 수 있는 서비스입니다.
위 이미지를 통해 알 수 있듯이 steady는 기술 스택, 모집 분야, 좋아요와 일대다 관계를 맺고 있습니다. 이러한 관계를 맺고 있는 데이터들이 존재할 때 동적으로 필터링 또는 검색 조건을 통해 조회하기 위해서 QueryDsl을 사용하였습니다.
QueryDsl을 통해 작성한 메서드와 당시 DB 상황은 다음과 같습니다.
메서드에 대해서 간단히 설명하자면 steady_stack과 steady_position의 경우 항상 존재하기 때문에 Inner Join 해주었으며, steady_like의 경우 좋아요를 누르지 않았다면 존재하지 않는 경우도 있기 때문에 Left Join 을 사용하였습니다.
필터링 & 검색 조건을 처리하는 부분은 wherer 절의 searchCondition() 메서드이며, 페이징 조건은 offset = 0, limit = 10 입니다.
| 테이블 | 데이터 수 |
| steady | 125 |
| steady_stacks | 208 |
| steady_position | 182 |
| steady_likes | 20 |
위 메서드를 실행 시킨 결과는 다음과 같습니다.
페이징 조건에 따라 10개의 각기 다른 데이터가 조회되길 기대했는데 결과는 그렇지 못한 것을 확인할 수 있었습니다. DB 상에서 일대다 관계를 Join 하여 조회하면 카테시안 곱이 발생하여 중복된 데이터가 발생하기 때문이었습니다.
다행히도 해당 문제는 조회 메서드에 distinct를 추가하여 중복된 값을 제거하고 조회할 수 있도록 하면 쉽게 해결할 수 있는 문제였습니다. 그런데, 또 다른 문제점을 발견하게 됩니다.
N + 1 (feat. Fetch Join과 Paging)
메서드 실행 결과에 대한 로그 정보입니다. 요청 총 소요 시간이 553ms 로 프로젝트 환경마다 요총 소요 시간의 최적값이 상이하겠지만, 일반적으로는 300ms 이하로 나오는 것이 좋다고 알고 있습니다. 따라서 요청을 처리하는 데에 꽤나 많은 시간이 걸리고 있다는 것을 확인할 수 있었으며, 총 쿼리 카운트가 56개로 너무 많은 쿼리를 발생시키고 있는 것을 확인할 수 있었습니다.
이는 조회한 엔티티를 지연 초기화 하는 과정에서 N + 1 문제가 발생하고 었었기 때문이었습니다. N + 1 문제는 JPA를 사용하는 개발자들에게 친숙한 문제이기 때문에 저 역시 따로 깊은 고민을 하지 않고 Fetch Join 을 사용하여 해결하려고 하였습니다.
하지만 Fetch Join은 연관관계가 설정되지 않은 경우에는 적용되지 않는다는 문제점이 존재했습니다. 이는 Fetch Join의 동작 방식 때문인데, 엔티티를 조회할 때 프록시로 조회되어야 할 필드(fetch = FetchType.Lazy 가 적용된 필드)를 프록시가 아닌 실제 엔티티를 조회하여 넣어주는 방식으로 동작하기 때문입니다.
또한, 컬렉션에 Fetch Join을 사용하면 다음과 같은 경고문을 만나게 됩니다.
단순히 경고문만 출력되는 것이 아니라 아래와 같이 쿼리에도 변경점이 발생하게 됩니다.
마지막 라인의 order by 절에서 offset 과 limit 에 대한 값이 사라진 것을 확인할 수 있습니다. 왜 이런 변경점이 발생하는 것일까요?
이는 일대다 관계와 같은 컬렉션 관계를 Fetch Join 하게 되면 데이터의 수가 변하기 때문에 (위의 카테시안 곱 상황) 몇 개의 row를 가져와 페이징 처리를 해야하는지 애플리케이션에서는 예측할 수 없기 때문입니다. 예측이 불가능하기 때문에 페이징 처리를 하기 위해서 Pageable 조건인 offset 과 limit을 무시하고 모든 결과를 가져와 메모리에 올린 후 페이징 처리를 진행하기 때문에 위와 같은 경고문의 출력과 쿼리의 변경이 발생하는 것이었습니다.
추가적으로 데이터의 수를 예측할 수 없기 때문에 하나의 컬렉션에 대해서만 적용이 가능합니다.
default_batch_fetch_size
Fetch Join 을 사용하여 해결하는 것에 실패하였기 때문에 또 다른 해결 방법인 default_batch_fetch_size 설정을 이용하여 해결을 시도하였습니다. 해당 설정은 지연 로딩으로 발생하는 쿼리를 지정한 크기만큼 모아두었다가 크기에 도달하면 쿼리의 in절을 통해 모아둔 쿼리를 처리하여 쿼리 발생을 최적화 해주는 기능입니다.
실행 결과 요청 소요 시간이 553ms -> 90ms 로 단축되었으며, 총 쿼리 카운트도 56 -> 10으로 줄어든 것을 확인할 수 있었습니다. 그런데 이 default_batch_fetch_size 의 값을 얼마로 주느냐에 따라 성능에 유의미한 차이가 있다고 하여 테스트를 해보았지만, 큰 차이를 확인할 수 없어서 해당 설정에 대해서 좀 더 조사를 해보았습니다.
우선, 데이터 베이스는 성능을 최적화하기 위해 실행한 SQL 구문과 파싱된 결과를 내부에 캐싱을 하게 됩니다. 이렇게 함으로써 같은 모양의 SQL 구문이 실행될 때 캐싱된 정보를 그대로 사용하여 효율적인 동작을 할 수 있게 되는 것입니다. Hibernate 역시 이러한 점을 인지하고 default_batch_fetch_size를 사용할 때 in 절에 들어올 수 있는 파라미터의 개수를 캐싱하여 최적화를 진행하였습니다. 이 값은 1 ~ 10, 12, 25, 50, 100 으로 총 14개의 형태를 캐싱하게 되는데, 예를 들어 값을 18로 설정하고 18개의 데이터를 조회하면 in 절에 12개의 파라미터를 받는 쿼리와 6개를 받는 쿼리로 나뉘어 조회가 일어나게 되는 것입니다.
하지만 공식문서를 찾아보니 해당 옵션을 조절할 수 있는 batch_fetch_style 설정이 Hiberante 6.2 버전부터 deprecated 된 것을 확인할 수 있었습니다. 이는 default_batch_fetch_size의 동작이 변경되었기 때문인데, 기존의 where in(?) 방식으로 동작하던 것이 where array_contains(array[], ?) 방식으로 동작하게끔 변경되었다고 합니다. 이렇게 동작하면 단 2개의 파라미터만을 받아들이기 때문에 SQL 최적화에도 보다 유리하다고 합니다. (참고 : 인프런 커뮤니티)
이러한 정보를 토대로 저는 다음과 같이 정리하였습니다.
1. Hibernate 6.2 부터 default_batch_fetch_size의 동작 방식이 변경되었기 때문에 옵션 크기에 따라 SQL 최적화가 변경되진 않는다. (항상 2개의 파라미터만을 받아들이기에)
2. 크기는 몇 개의 쿼리를 모아두었다가 한 번에 쿼리를 날릴 것인가에 대한 설정이므로, DB가 부하를 견딜 수 있을만큼 지정해주면 된다. 일반적으로는 100 ~ 1000 으로 설정하길 권장한다.
3. 현재 프로젝트에서는 하나의 steady를 조회할 때 지연 초기화되는 데이터의 수가 100개를 넘어가지 않기 때문에 우선 100으로 지정한다.
아쉬운 점 (Projection, @EntityGraph)
단순히 JPA 만을 사용하는 것이 아니라 QueryDsl도 같이 사용하고 있었기 때문에 N + 1 문제가 발생하였을 때 Fetch Join만을 떠올리는 것이 아니라 Projection 을 통한 해결방법도 떠올렸으면 좋지 않았을까 하는 아쉬움을 느끼게 되었습니다. Projection을 사용하면 SELECT 절에 대상 컬럼을 포함시켜 한 번에 조회하기 때문에 N + 1 문제를 해결하기에 적합한 또 다른 선택지가 될 수 있다고 생각합니다.
@EntityGraph 를 사용한 방법 역시 N + 1 문제의 대응책으로 많이 알려진 방법인데, 이 역시 모든 결과를 조회한 후 메모리에 올려서 페이징 처리를 진행하기 때문에 해결책으로서는 적합하지 않았습니다. 또한, fetchType을 Eager로 변환하는 방식으로 동작하며 LEFT OUTER JOIN을 수행하기 때문에 데이터에 null이 존재할 수 있습니다.
'Spring' 카테고리의 다른 글
| 이벤트를 좀 더 제대로 다뤄보자 (feat. MSA & EDA) (2) | 2024.04.22 |
|---|---|
| 동시성 테스트를 통한 성능 개선하기 (2) - Spring Event (2) | 2024.04.04 |
| 조회 성능 최적화(3) - QueryDsl : SQL (0) | 2024.03.16 |
| 테스트 객체 생성 라이브러리 Instancio, Fixture Monkey (feat. Test Fixture) (0) | 2024.02.05 |